Case for NoSQL - Cassandra Hands-On
1. Solution Architecture
In this exercise, we deploy a Cassandra on a 3 node setup on AWS. We simulate a node failure and try to reason out the resiliency of the Cassandra architecture
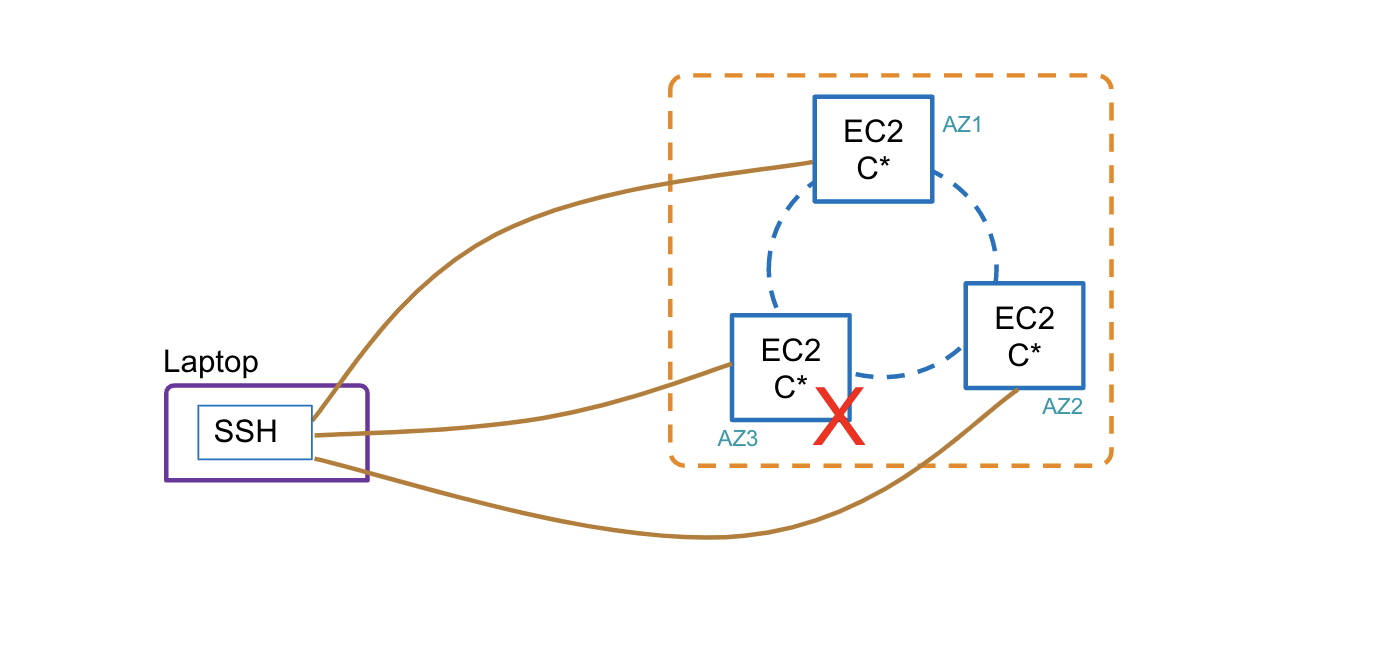
2. Bringing up a Cassandra Cluster
In this section, we will cover the steps involved in creating a new security group, bring up 3 EC2 instances, configure Cassandra on the nodes and bring up the cluster.
2.1 Creating a new security group
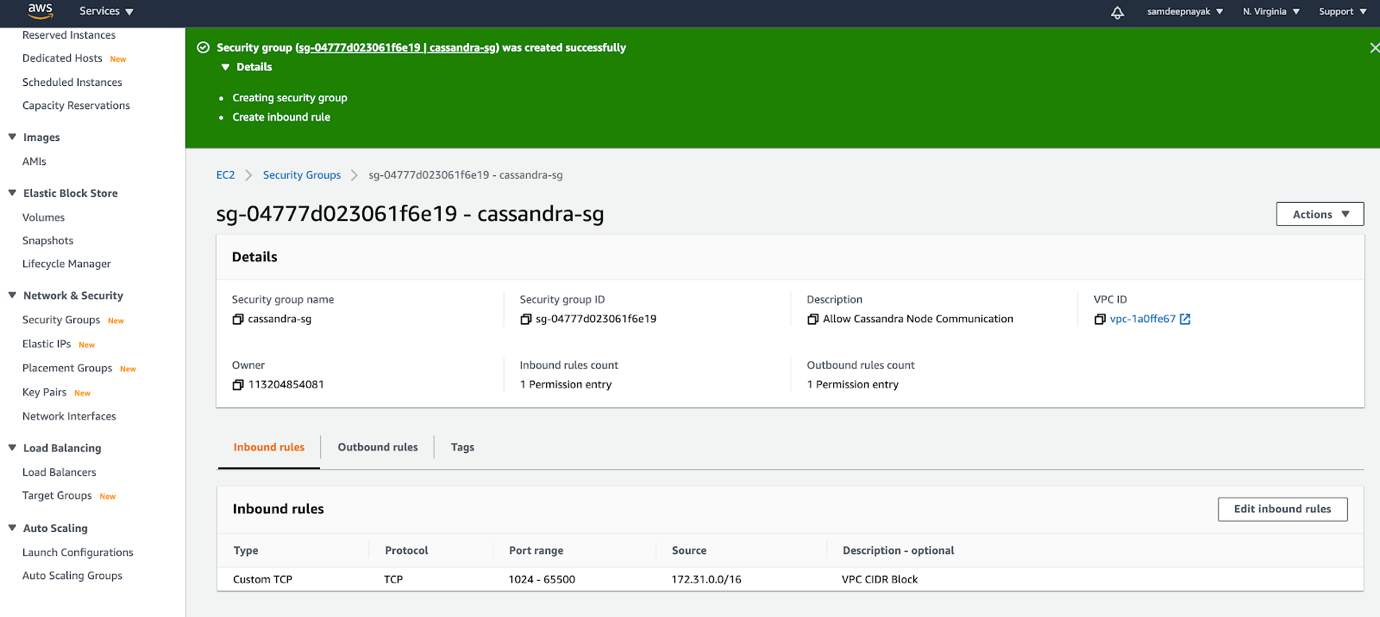
Created a new security group “cassandra-sg” where the inbound ports from 1024-65500 are open for all IP addresses in the VPC CIDR block
2.2 Set up EC2
We have created 3 EC2 instances each running in a different availability zones. We also added 2 security groups to these EC2 instances. One to allow communication between the 3 nodes within the VPC CIDR and the other to allow ssh to the nodes.
I have used the SKL-Ubuntu-Cassandra from community AMI for the image. This has all the pre-requisite software installed
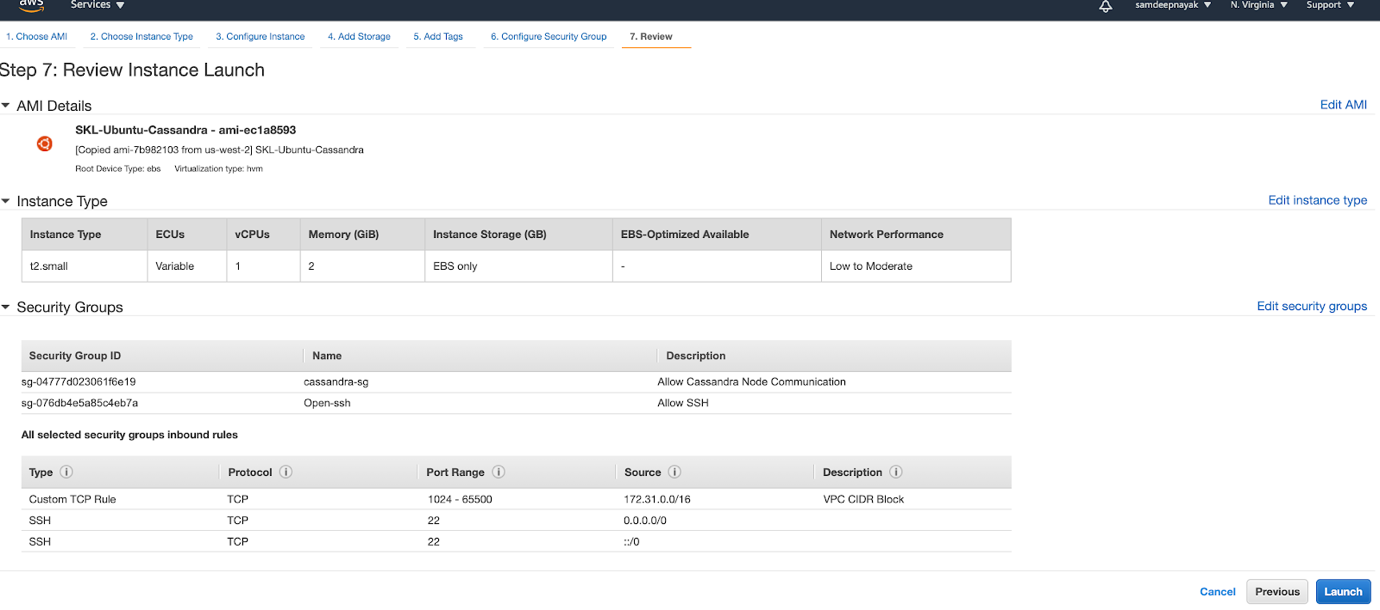
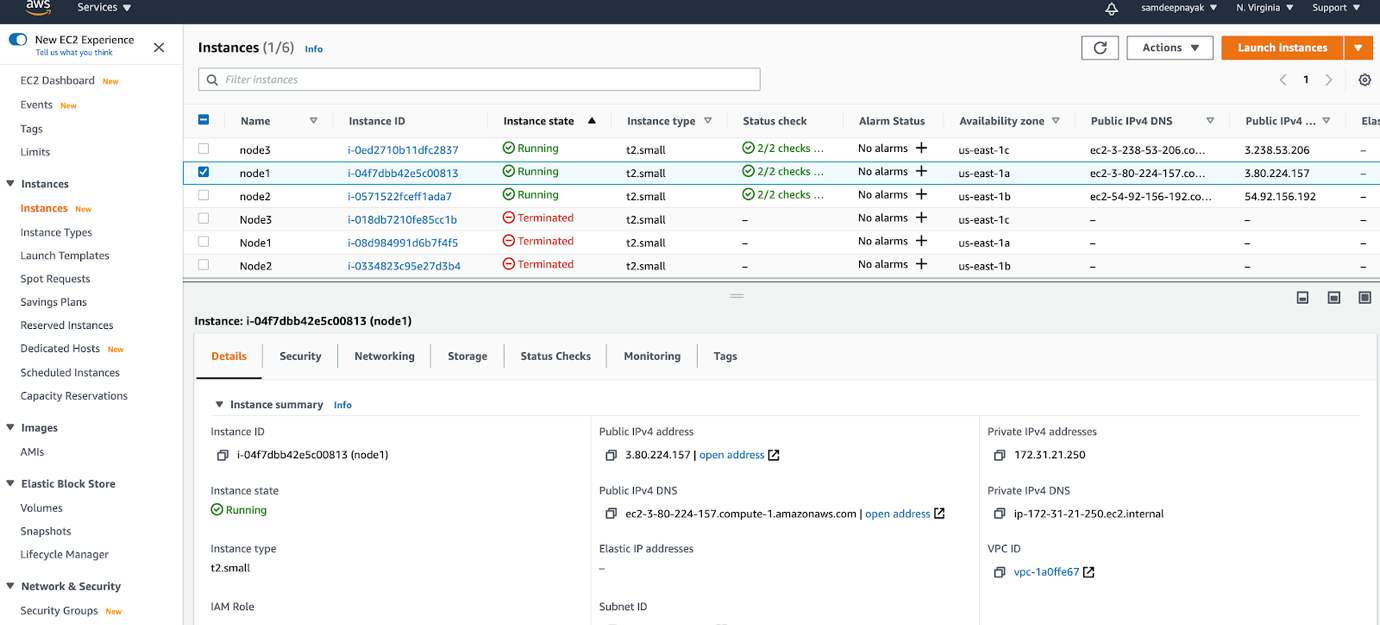
We login to each of the nodes and verify that the EC2 instances are up and running as expected.
2.3 Configure Cassandra
We configure the Cassandra parameters on each of the EC2 nodes. We are emulating a single data centre with 3 rack configuration in this example. The name of the cluster is GL-Cluster
On the first EC2 instance, configure the parameters as below. We will use the primary address of the node1 for the seed list. We are creating only one Datacenter and calling it as dc1 and rack will be called as r1
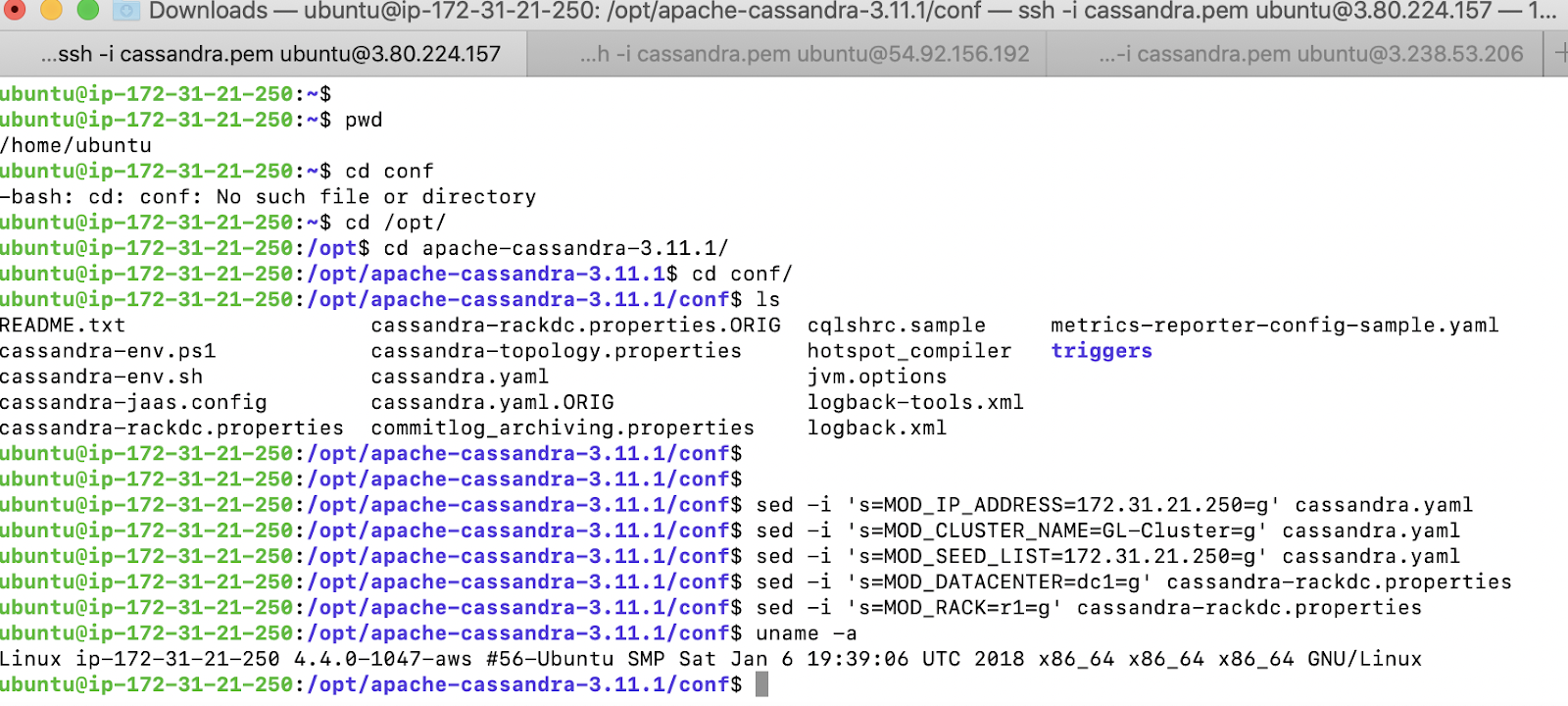
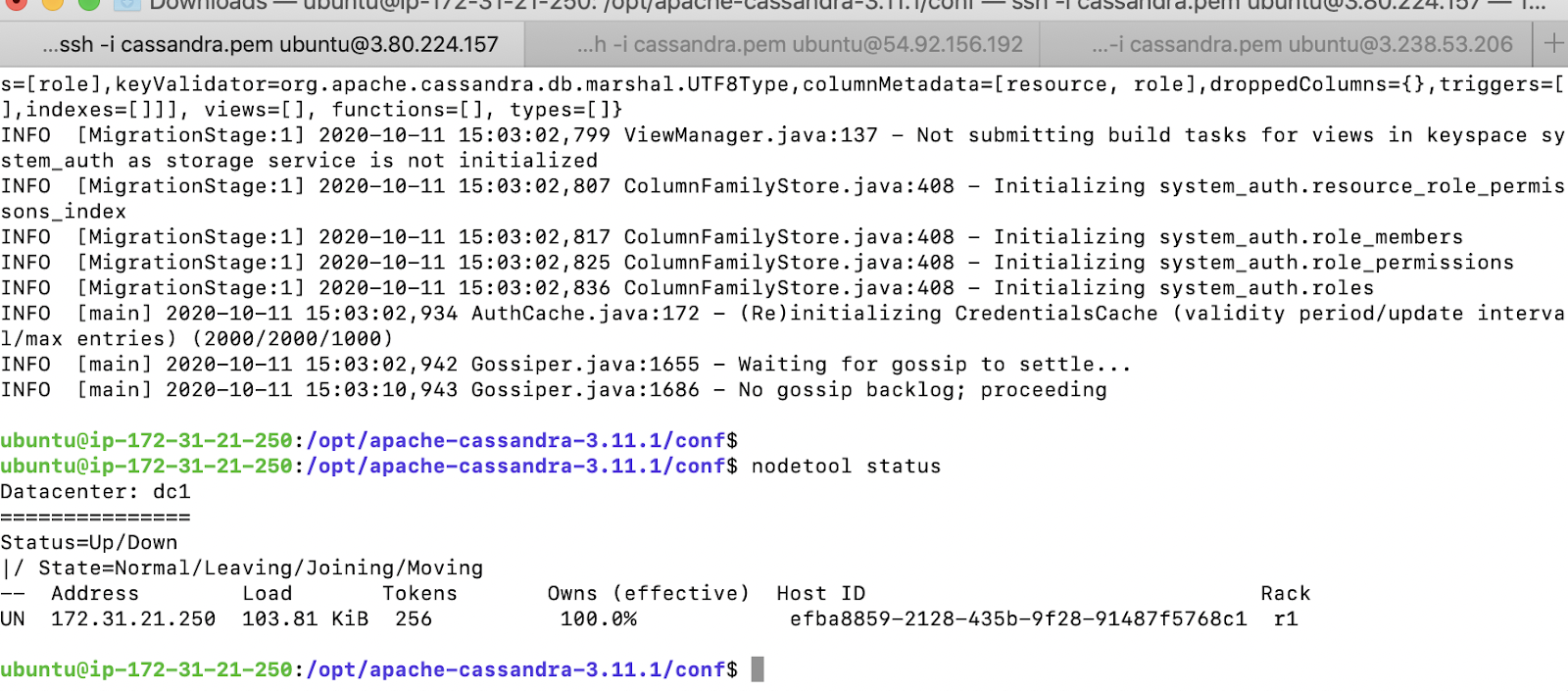
We start Cassandra and verify the status using the nodetool command
On the second EC2 instance, we configure the parameters as below. The configuration is very similar to configuring the node 1 except for the rack which we represent as r2. We will use the node 1 as the seed node
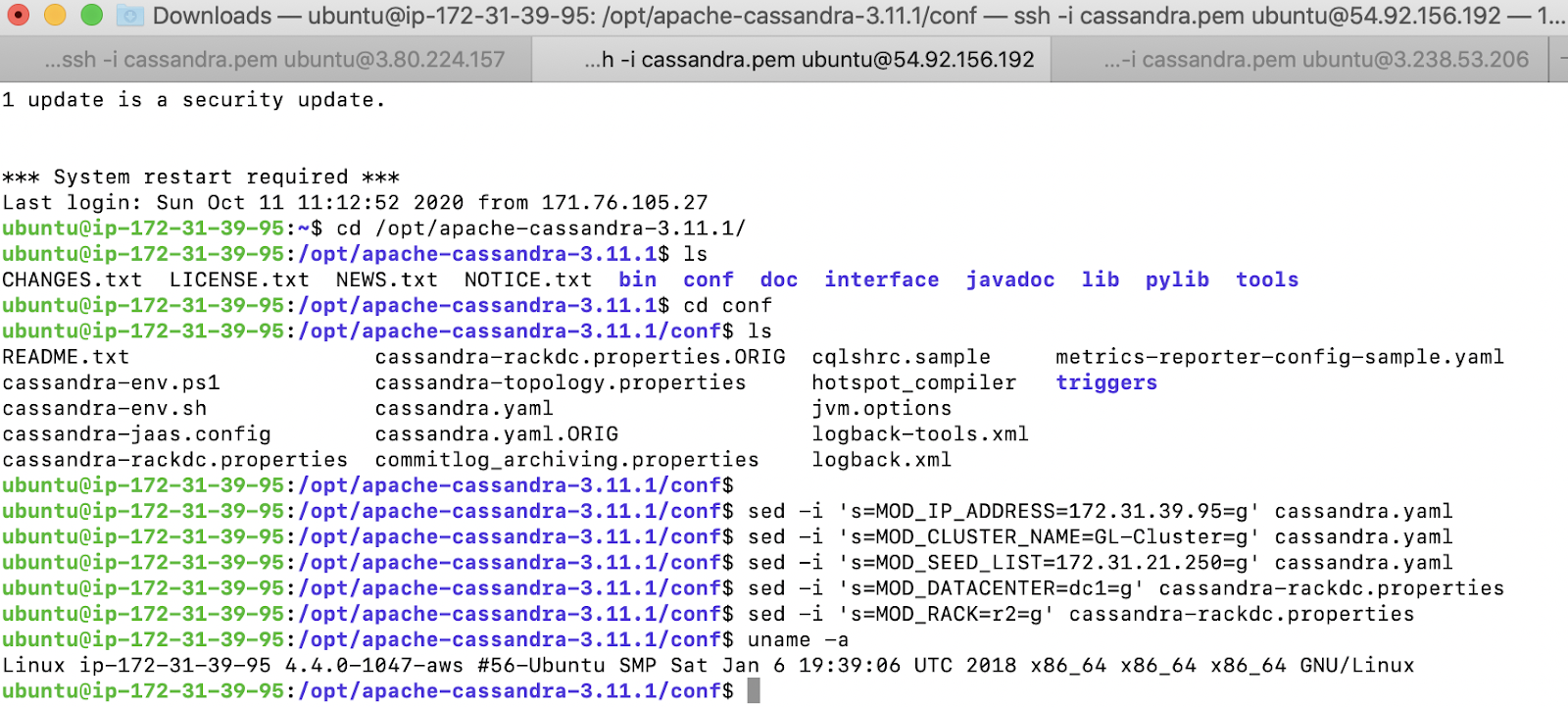
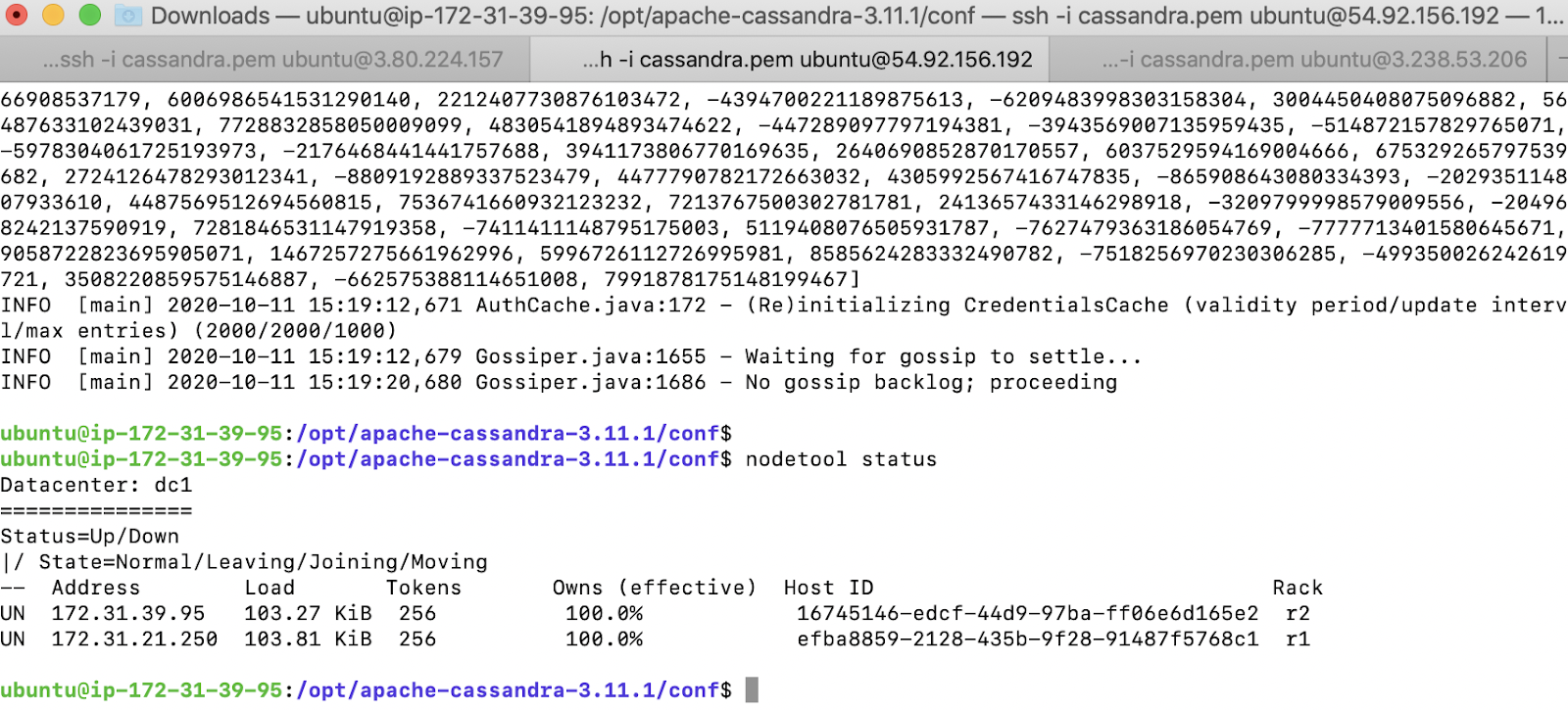
We start Cassandra and verify the status using the nodetool command. We can now see both nodes being part of the cluster
On the third EC2 instance, configure the parameters as below. The configuration is very similar to configuring the node 1 except for the rack which we represent as r3. We will use the node 1 as the seed node
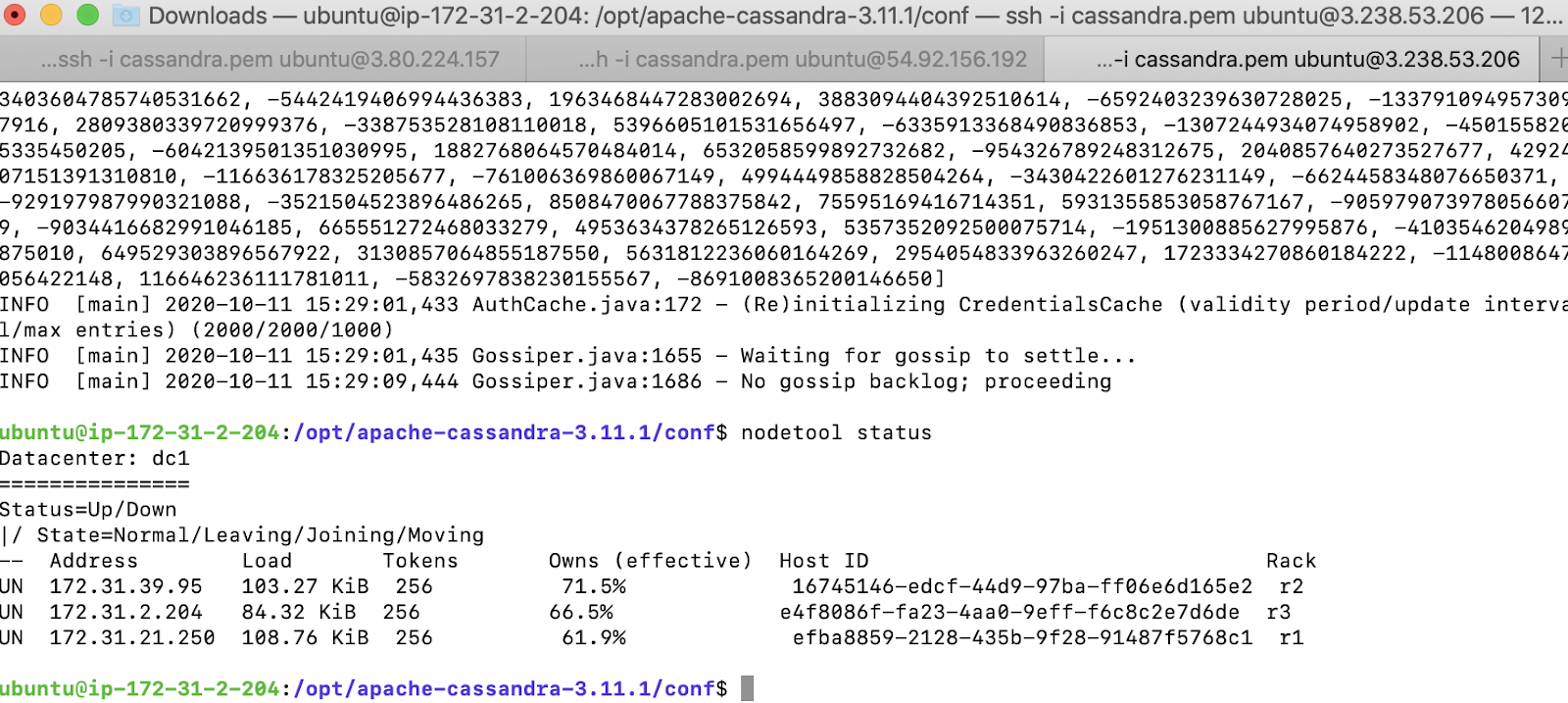
We start Cassandra and verify the status using the nodetool command. We can now see all the 3 nodes being part of the cluster
2.4 Verify the node failure behaviours
1. Start the cqlsh
We use the below commands to start cqlsh
ubuntu\@ip-172-31-21-250:~$ cqlsh 172.31.21.250 -u cassandra -p cassandra
Connected to GL-Cluster at 172.31.21.250:9042.
[cqlsh 5.0.1 | Cassandra 3.11.1 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cassandra\@cqlsh>
2. Increase the replication factor of the system auth table to 3
In the cqlsh, increase the replication factor
cassandra\@cqlsh> ALTER KEYSPACE "system_auth" WITH REPLICATION = {'class':'NetworkTopologyStrategy', 'dc1':3};
3. Create the keyspace and table
cassandra\@cqlsh> CREATE KEYSPACE IF NOT EXISTS starfleet WITH replication = {'class':'NetworkTopologyStrategy', 'dc1':3};
cassandra\@cqlsh> DESCRIBE KEYSPACE starfleet ;
CREATE KEYSPACE starfleet WITH replication = {'class': 'NetworkTopologyStrategy', 'dc1': '3'} AND durable_writes = true;
cassandra\@cqlsh>
cassandra\@cqlsh> CREATE TABLE starfleet.user (
... user_id VARCHAR,
... location VARCHAR,
... display_name VARCHAR,
... first_name VARCHAR,
... last_name VARCHAR,
... PRIMARY KEY (user_id, location)
... );
4. Insert the sample record 1
cassandra\@cqlsh> INSERT INTO starfleet.user (user_id,location,display_name,first_name,last_name)
... VALUES ('u1','earth1','Kirk','William','Shatner');
5. Insert the sample record 2
cassandra\@cqlsh> INSERT INTO starfleet.user (user_id,location,display_name,first_name,last_name)
... VALUES ('u2','vulcan','Spock','Leonard','Nimoy');
After the records are inserted, you can verify that they are present with the following command
cassandra\@cqlsh> select * from starfleet.user ;
user_id | location | display_name | first_name | last_name
---------+----------+--------------+------------+-----------
u2 | vulcan | Spock | Leonard | Nimoy
u1 | earth1 | Kirk | William | Shatner
(2 rows)
cassandra\@cqlsh>
6. Check the consistency level
cassandra\@cqlsh> CONSISTENCY
Current consistency level is ONE.
7. Set the consistency level to ALL
cassandra\@cqlsh> CONSISTENCY ALL
Consistency level set to ALL.
Verify that the consistency level has been updated in the system
cassandra\@cqlsh> CONSISTENCY
Current consistency level is ALL.
cassandra\@cqlsh>
8. Check the value of the record u2
cassandra\@cqlsh> Select * from starfleet.user where user_id = 'u2';
user_id | location | display_name | first_name | last_name
---------+----------+--------------+------------+-----------
u2 | vulcan | Spock | Leonard | Nimoy
(1 rows)
cassandra\@cqlsh>
9. Stop the Cassandra daemon on the 3rd Node
Go to the 3^rd^ EC2 instance and induce a failure. Verify nodetool represents the status of the node as down
ubuntu\@ip-172-31-2-204:~$ nodetool stopdaemon
WARN 16:17:19,260 Small commitlog volume detected at /opt/cassandra-data/commitlog; setting commitlog_total_space_in_mb to 1969. You can override this in cassandra.yaml
WARN 16:17:19,264 Small cdc volume detected at /opt/cassandra-data/cdc_raw; setting cdc_total_space_in_mb to 984. You can override this in cassandra.yaml
WARN 16:17:19,264 Only 5.196GiB free across all data volumes. Consider adding more capacity to your cluster or removing obsolete snapshots
Cassandra has shutdown.
ubuntu\@ip-172-31-2-204:~$ uname -a
Linux ip-172-31-2-204 4.4.0-1047-aws #56-Ubuntu SMP Sat Jan 6 19:39:06 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
ubuntu\@ip-172-31-2-204:~$
ubuntu\@ip-172-31-39-95:~$ nodetool status
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 172.31.39.95 115.21 KiB 256 100.0% 16745146-edcf-44d9-97ba-ff06e6d165e2 r2
DN 172.31.2.204 96.36 KiB 256 100.0% e4f8086f-fa23-4aa0-9eff-f6c8c2e7d6de r3
UN 172.31.21.250 172.53 KiB 256 100.0% efba8859-2128-435b-9f28-91487f5768c1 r1
ubuntu\@ip-172-31-39-95:~$
10. Check the value of the same record again
cassandra\@cqlsh> Select * from starfleet.user where user_id = 'u2';
NoHostAvailable:
cassandra\@cqlsh> Select * from starfleet.user where user_id = 'u2';
NoHostAvailable:
cassandra\@cqlsh>
11. Observation
When consistency is set to All, Cassandra will try to complete the read record only after all the replicas have responded. Since Node 3 is down, it will not be able respond. Hence Cassandra will fail to retrieve the record.
We can confirm the behaviour by bringing back the node online as below.
Start the Cassandra on Node 3 again
INFO [GossipStage:1] 2020-10-11 16:29:16,019 TokenMetadata.java:479 - Updating topology for /172.31.21.250
INFO [HANDSHAKE-/172.31.39.95] 2020-10-11 16:29:16,075 OutboundTcpConnection.java:560 - Handshaking version with /172.31.39.95
INFO [main] 2020-10-11 16:29:23,300 Gossiper.java:1686 - No gossip backlog; proceeding
ubuntu\@ip-172-31-2-204:~$ uname -a
Linux ip-172-31-2-204 4.4.0-1047-aws #56-Ubuntu SMP Sat Jan 6 19:39:06 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
ubuntu\@ip-172-31-2-204:~$ nodetool status
Datacenter: dc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 172.31.39.95 216.23 KiB 256 100.0% 16745146-edcf-44d9-97ba-ff06e6d165e2 r2
UN 172.31.2.204 207.36 KiB 256 100.0% e4f8086f-fa23-4aa0-9eff-f6c8c2e7d6de r3
UN 172.31.21.250 172.53 KiB 256 100.0% efba8859-2128-435b-9f28-91487f5768c1 r1
ubuntu\@ip-172-31-2-204:~$
Try to retrieve the record now and this will succeed
cassandra\@cqlsh> Select * from starfleet.user where user_id = 'u2';
user_id | location | display_name | first_name | last_name
---------+----------+--------------+------------+-----------
u2 | vulcan | Spock | Leonard | Nimoy
(1 rows)
cassandra\@cqlsh>
This confirms our assumption that CONSISTENCY ALL will require all the nodes to be healthy
12. Change the consistency to Quorum and try to retrieve the record
Before we change the CONSISTENCY, let us take back the set up with the failure condition as above
ubuntu\@ip-172-31-2-204:~$ nodetool stopdaemon
WARN 16:33:18,689 Small commitlog volume detected at /opt/cassandra-data/commitlog; setting commitlog_total_space_in_mb to 1969. You can override this in cassandra.yaml
WARN 16:33:18,692 Small cdc volume detected at /opt/cassandra-data/cdc_raw; setting cdc_total_space_in_mb to 984. You can override this in cassandra.yaml
WARN 16:33:18,693 Only 5.197GiB free across all data volumes. Consider adding more capacity to your cluster or removing obsolete snapshots
Cassandra has shutdown.
ubuntu\@ip-172-31-2-204:~$ uname -a
Linux ip-172-31-2-204 4.4.0-1047-aws #56-Ubuntu SMP Sat Jan 6 19:39:06 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
ubuntu\@ip-172-31-2-204:~$
cassandra\@cqlsh> Select * from starfleet.user where user_id = 'u2';
NoHostAvailable:
cassandra\@cqlsh>
Set the CONSISTENCY to QUORUM now
cassandra\@cqlsh> CONSISTENCY QUORUM
Consistency level set to QUORUM.
cassandra\@cqlsh>
13. Select * from starfleet.user where user_id = 'u2';
We are able to retrieve the record now even though one of the node is down
cassandra\@cqlsh> Select * from starfleet.user where user_id = 'u2';
user_id | location | display_name | first_name | last_name
---------+----------+--------------+------------+-----------
u2 | vulcan | Spock | Leonard | Nimoy
(1 rows)
cassandra\@cqlsh>
14. Observation
Quorum is calculated as below.
quorum = (sum_of_replication_factors / 2) + 1
where the sum of all the replication_factor settings for each datacenter is the sum_of_replication_factors.
sum_of_replication_factors = datacenter1_RF + datacenter2_RF + . . . + datacentern_RF
In our case, we have only 1 datacenter. Our replication factor is 3.
Based on the above calculation, our quorum in this example will be 2 nodes. So the cluster can tolerate 1 replica failure.
Hence we were able to retrieve the data even when one of the node failed.